-
Partie 5
Les Boucles« Les premiers 90% du code prennent les premiers 90% du temps de développement. Les 10% restants prennent les autres 90% du temps de développement » - Tom Cargill
Et ça y est, on y est, on est arrivés, la voilà, c’est Broadway, la quatrième et dernière structure : ça est les boucles. Si vous voulez épater vos amis, vous pouvez également parler de structures répétitives, voire carrément de structures itératives. Ca calme, hein ? Bon, vous faites ce que vous voulez, ici on est entre nous, on parlera de boucles.Les boucles, c'est généralement le point douloureux de l'apprenti programmeur. C'est là que ça coince, car autant il est assez facile de comprendre comment fonctionnent les boucles, autant il est souvent long d'acquérir les réflexes qui permettent de les élaborer judicieusement pour traiter un problème donné.On peut dire en fait que les boucles constituent la seule vraie structure logique caractéristique de la programmation. Si vous avez utilisé un tableur comme Excel, par exemple, vous avez sans doute pu manier des choses équivalentes aux variables (les cellules, les formules) et aux tests (la fonction SI…). Mais les boucles, ça, ça n'a aucun équivalent. Cela n'existe que dans les langages de programmation proprement dits.Le maniement des boucles, s'il ne différencie certes pas l'homme de la bête (il ne faut tout de même pas exagérer), est tout de même ce qui sépare en informatique le programmeur de l'utilisateur, même averti.Alors, à vos futures – et inévitables - difficultés sur le sujet, il y a trois remèdes : de la rigueur, de la patience, et encore de la rigueur !Prenons le cas d’une saisie au clavier (une lecture), où par exemple, le programme pose une question à laquelle l’utilisateur doit répondre par O (Oui) ou N (Non). Mais tôt ou tard, l’utilisateur, facétieux ou maladroit, risque de taper autre chose que la réponse attendue. Dès lors, le programme peut planter soit par une erreur d’exécution (parce que le type de réponse ne correspond pas au type de la variable attendu) soit par une erreur fonctionnelle (il se déroule normalement jusqu’au bout, mais en produisant des résultats fantaisistes).Alors, dans tout programme un tant soit peu sérieux, on met en place ce qu’on appelle un contrôle de saisie, afin de vérifier que les données entrées au clavier correspondent bien à celles attendues par l’algorithme.A vue de nez, on pourrait essayer avec un SI. Voyons voir ce que ça donne :Variable Rep en Caractère
Début
Ecrire "Voulez vous un café ? (O/N)"
Lire Rep
Si Rep <> "O" et Rep <> "N" Alors
Ecrire "Saisie erronnée. Recommencez"
Lire Rep
FinSi
FinC’est impeccable. Du moins tant que l’utilisateur a le bon goût de ne se tromper qu’une seule fois, et d’entrer une valeur correcte à la deuxième demande. Si l’on veut également bétonner en cas de deuxième erreur, il faudrait rajouter un SI. Et ainsi de suite, on peut rajouter des centaines de SI, et écrire un algorithme aussi lourd qu’une blague des Grosses Têtes, on n’en sortira pas, il y aura toujours moyen qu’un acharné flanque le programme par terre.La solution consistant à aligner des SI… en pagaille est donc une impasse. La seule issue est donc de flanquer une structure de boucle, qui se présente ainsi :TantQue booléen
…
Instructions
…
FinTantQueLe principe est simple : le programme arrive sur la ligne du TantQue. Il examine alors la valeur du booléen (qui, je le rappelle, peut être une variable booléenne ou, plus fréquemment, une condition). Si cette valeur est VRAI, le programme exécute les instructions qui suivent, jusqu’à ce qu’il rencontre la ligne FinTantQue. Il retourne ensuite sur la ligne du TantQue, procède au même examen, et ainsi de suite. Le manège enchanté ne s’arrête que lorsque le booléen prend la valeur FAUX.Illustration avec notre problème de contrôle de saisie. Une première approximation de la solution consiste à écrire :Variable Rep en Caractère
Début
Ecrire "Voulez vous un café ? (O/N)"
TantQue Rep <> "O" et Rep <> "N"
Lire Rep
FinTantQue
FinLà, on a le squelette de l’algorithme correct. Mais de même qu’un squelette ne suffit pas pour avoir un être vivant viable, il va nous falloir ajouter quelques muscles et organes sur cet algorithme pour qu’il fonctionne correctement.Son principal défaut est de provoquer une erreur à chaque exécution. En effet, l’expression booléenne qui figure après le TantQue interroge la valeur de la variable Rep. Malheureusement, cette variable, si elle a été déclarée, n’a pas été affectée avant l’entrée dans la boucle. On teste donc une variable qui n’a pas de valeur, ce qui provoque une erreur et l’arrêt immédiat de l’exécution. Pour éviter ceci, on n’a pas le choix : il faut que la variable Rep ait déjà été affectée avant qu’on en arrive au premier tour de boucle. Pour cela, on peut faire une première lecture de Rep avant la boucle. Dans ce cas, celle-ci ne servira qu’en cas de mauvaise saisie lors de cette première lecture. L’algorithme devient alors :Variable Rep en Caractère
Début
Ecrire "Voulez vous un café ? (O/N)"
Lire Rep
TantQue Rep <> "O" et Rep <> "N"
Lire Rep
FinTantQue
FinUne autre possibilité, fréquemment employée, consiste à ne pas lire, mais à affecter arbitrairement la variable avant la boucle. Arbitrairement ? Pas tout à fait, puisque cette affectation doit avoir pour résultat de provoquer l’entrée obligatoire dans la boucle. L’affectation doit donc faire en sorte que le booléen soit mis à VRAI pour déclencher le premier tour de la boucle. Dans notre exemple, on peut donc affecter Rep avec n’importe quelle valeur, hormis « O » et « N » : car dans ce cas, l’exécution sauterait la boucle, et Rep ne serait pas du tout lue au clavier. Cela donnera par exemple :Variable Rep en Caractère
Début
Rep ← "X"
Ecrire "Voulez vous un café ? (O/N)"
TantQue Rep <> "O" et Rep <> "N"
Lire Rep
FinTantQue
FinCette manière de procéder est à connaître, car elle est employée très fréquemment.Il faut remarquer que les deux solutions (lecture initiale de Rep en dehors de la boucle ou affectation de Rep) rendent toutes deux l’algorithme satisfaisant, mais présentent une différence assez importante dans leur structure logique.En effet, si l’on choisit d’effectuer une lecture préalable de Rep, la boucle ultérieure sera exécutée uniquement dans l’hypothèse d’une mauvaise saisie initiale. Si l’utilisateur saisit une valeur correcte à la première demande de Rep, l’algorithme passera sur la boucle sans entrer dedans.En revanche, avec la deuxième solution (celle d’une affectation préalable de Rep), l’entrée de la boucle est forcée, et l’exécution de celle-ci, au moins une fois, est rendue obligatoire à chaque exécution du programme. Du point de vue de l’utilisateur, cette différence est tout à fait mineure ; et à la limite, il ne la remarquera même pas. Mais du point de vue du programmeur, il importe de bien comprendre que les cheminements des instructions ne seront pas les mêmes dans un cas et dans l’autre.Pour terminer, remarquons que nous pourrions peaufiner nos solutions en ajoutant des affichages de libellés qui font encore un peu défaut. Ainsi, si l’on est un programmeur zélé, la première solution (celle qui inclut deux lectures de Rep, une en dehors de la boucle, l’autre à l’intérieur) pourrait devenir :Variable Rep en Caractère
Début
Ecrire "Voulez vous un café ? (O/N)"
Lire Rep
TantQue Rep <> "O" et Rep <> "N"
Ecrire "Vous devez répondre par O ou N. Recommencez"
Lire Rep
FinTantQue
Ecrire "Saisie acceptée"
FinQuant à la deuxième solution, elle pourra devenir :Variable Rep en Caractère
Début
Rep ← "X"
Ecrire "Voulez vous un café ? (O/N)"
TantQue Rep <> "O" et Rep <> "N"
Lire Rep
Si Rep <> "O" et Rep <> "N" Alors
Ecrire "Saisie Erronée, Recommencez"
FinSi
FinTantQue
FinLe Gag De La Journée
C’est d’écrire une structure TantQue dans laquelle le booléen n’est jamais VRAI. Le programme ne rentre alors jamais dans la superbe boucle sur laquelle vous avez tant sué !
Mais la faute symétrique est au moins aussi désopilante.
Elle consiste à écrire une boucle dans laquelle le booléen ne devient jamais FAUX. L’ordinateur tourne alors dans la boucle comme un dératé et n’en sort plus. Seule solution, quitter le programme avec un démonte-pneu ou un bâton de dynamite. La « boucle infinie » est une des hantises les plus redoutées des programmeurs. C’est un peu comme le verre baveur, le poil à gratter ou le bleu de méthylène : c’est éculé, mais ça fait toujours rire.
Cette faute de programmation grossière – mais fréquente - ne manquera pas d’égayer l’ambiance collective de cette formation… et accessoirement d’étancher la soif proverbiale de vos enseignants.Bon, eh bien vous allez pouvoir faire de chouettes algorithmes, déjà rien qu’avec ça…
Dans le dernier exercice, vous avez remarqué qu’une boucle pouvait être utilisée pour augmenter la valeur d’une variable. Cette utilisation des boucles est très fréquente, et dans ce cas, il arrive très souvent qu’on ait besoin d’effectuer un nombre déterminé de passages. Or, a priori, notre structure TantQue ne sait pas à l’avance combien de tours de boucle elle va effectuer (puisque le nombre de tours dépend de la valeur d’un booléen).C’est pourquoi une autre structure de boucle est à notre disposition :Variable Truc en Entier
Début
Truc ← 0
TantQue Truc < 15
Truc ← Truc + 1
Ecrire "Passage numéro : ", Truc
FinTantQue
FinEquivaut à :Variable Truc en Entier
Début
Pour Truc ← 1 à 15
Ecrire "Passage numéro : ", Truc
Truc Suivant
FinInsistons : la structure « Pour … Suivant » n’est pas du tout indispensable ; on pourrait fort bien programmer toutes les situations de boucle uniquement avec un « Tant Que ». Le seul intérêt du « Pour » est d’épargner un peu de fatigue au programmeur, en lui évitant de gérer lui-même la progression de la variable qui lui sert de compteur (on parle d’incrémentation, encore un mot qui fera forte impression sur votre entourage).Dit d’une autre manière, la structure « Pour … Suivant » est un cas particulier de TantQue : celui où le programmeur peut dénombrer à l’avance le nombre de tours de boucles nécessaires.Il faut noter que dans une structure « Pour … Suivant », la progression du compteur est laissée à votre libre disposition. Dans la plupart des cas, on a besoin d’une variable qui augmente de 1 à chaque tour de boucle. On ne précise alors rien à l’instruction « Pour » ; celle-ci, par défaut, comprend qu’il va falloir procéder à cette incrémentation de 1 à chaque passage, en commençant par la première valeur et en terminant par la deuxième.Mais si vous souhaitez une progression plus spéciale, de 2 en 2, ou de 3 en 3, ou en arrière, de –1 en –1, ou de –10 en –10, ce n’est pas un problème : il suffira de le préciser à votre instruction « Pour » en lui rajoutant le mot « Pas » et la valeur de ce pas (Le « pas » dont nous parlons, c’est le « pas » du marcheur, « step » en anglais).Naturellement, quand on stipule un pas négatif dans une boucle, la valeur initiale du compteur doit être supérieure à sa valeur finale si l’on veut que la boucle tourne ! Dans le cas contraire, on aura simplement écrit une boucle dans laquelle le programme ne rentrera jamais.Nous pouvons donc maintenant donner la formulation générale d’une structure « Pour ». Sa syntaxe générale est :Pour Compteur ← Initial à Final Pas ValeurDuPas
…
Instructions
…
Compteur suivantLes structures TantQue sont employées dans les situations où l’on doit procéder à un traitement systématique sur les éléments d’un ensemble dont on ne connaît pas d’avance la quantité, comme par exemple :- le contrôle d’une saisie
- la gestion des tours d’un jeu (tant que la partie n’est pas finie, on recommence)
- la lecture des enregistrements d’un fichier de taille inconnue(cf. Partie 9)
Les structures Pour sont employées dans les situations où l’on doit procéder à un traitement systématique sur les éléments d’un ensemble dont le programmeur connaît d’avance la quantité.Nous verrons dans les chapitres suivants des séries d’éléments appelés tableaux (parties 7 et 8) et chaînes de caractères (partie 9). Selon les cas, le balayage systématique des éléments de ces séries pourra être effectué par un Pour ou par un TantQue : tout dépend si la quantité d’éléments à balayer (donc le nombre de tours de boucles nécessaires) peut être dénombrée à l’avance par le programmeur ou non.On rigole, on rigole !De même que les poupées russes contiennent d’autres poupées russes, de même qu’une structure SI … ALORS peut contenir d’autres structures SI … ALORS, une boucle peut tout à fait contenir d’autres boucles. Y a pas de raison.Variables Truc, Trac en Entier
Début
Pour Truc ← 1 à 15
Ecrire "Il est passé par ici"
Pour Trac ← 1 à 6
Ecrire "Il repassera par là"
Trac Suivant
Truc Suivant
FinDans cet exemple, le programme écrira une fois "il est passé par ici" puis six fois de suite "il repassera par là", et ceci quinze fois en tout. A la fin, il y aura donc eu 15 x 6 = 90 passages dans la deuxième boucle (celle du milieu), donc 90 écritures à l’écran du message « il repassera par là ». Notez la différence marquante avec cette structure :Variables Truc, Trac en Entier
Début
Pour Truc ← 1 à 15
Ecrire "Il est passé par ici"
Truc Suivant
Pour Trac ← 1 à 6
Ecrire "Il repassera par là"
Trac Suivant
FinIci, il y aura quinze écritures consécutives de "il est passé par ici", puis six écritures consécutives de "il repassera par là", et ce sera tout.Des boucles peuvent donc être imbriquées (cas n°1) ou successives (cas n°2). Cependant, elles ne peuvent jamais, au grand jamais, être croisées. Cela n’aurait aucun sens logique, et de plus, bien peu de langages vous autoriseraient ne serait-ce qu’à écrire cette structure aberrante. Variables Truc, Trac en Entier
Variables Truc, Trac en Entier
Pour Truc ← …
instructions
Pour Trac ← …
instructions
Truc Suivant
instructions
Trac SuivantPourquoi imbriquer des boucles ? Pour la même raison qu’on imbrique des tests. La traduction en bon français d’un test, c’est un « cas ». Eh bien un « cas » (par exemple, « est-ce un homme ou une femme ? ») peut très bien se subdiviser en d’autres cas (« a-t-il plus ou moins de 18 ans ? »).De même, une boucle, c’est un traitement systématique, un examen d’une série d’éléments un par un (par exemple, « prenons tous les employés de l’entreprise un par un »). Eh bien, on peut imaginer que pour chaque élément ainsi considéré (pour chaque employé), on doive procéder à un examen systématique d’autre chose (« prenons chacune des commandes que cet employé a traitées »). Voilà un exemple typique de boucles imbriquées : on devra programmer une boucle principale (celle qui prend les employés un par un) et à l’intérieur, une boucle secondaire (celle qui prend les commandes de cet employé une par une).Dans la pratique de la programmation, la maîtrise des boucles imbriquées est nécessaire, même si elle n’est pas suffisante. Tout le contraire d’Alain Delon, en quelque sorte.Examinons l’algorithme suivant :Variable Truc en Entier
Début
Pour Truc ← 1 à 15
Truc ← Truc * 2
Ecrire "Passage numéro : ", Truc
Truc Suivant
FinVous remarquerez que nous faisons ici gérer « en double » la variable Truc, ces deux gestions étant contradictoires. D’une part, la lignePour…augmente la valeur de Truc de 1 à chaque passage. D’autre part la ligneTruc ← Truc * 2double la valeur de Truc à chaque passage. Il va sans dire que de telles manipulations perturbent complètement le déroulement normal de la boucle, et sont causes, sinon de plantages, tout au moins d’exécutions erratiques.Le Gag De La Journée
Il consiste donc à manipuler, au sein d’une boucle Pour, la variable qui sert de compteur à cette boucle. Cette technique est à proscrire absolument… sauf bien sûr, si vous cherchez un prétexte pour régaler tout le monde au bistrot.
Mais dans ce cas, n’ayez aucune inhibition, proposez-le directement, pas besoin de prétexte. votre commentaire
votre commentaire
-
Partie 4
Encore de la Logique« La programmation peut être un plaisir ; de même que la cryptographie. Toutefois, il faut éviter de combiner les deux. » - Kreitzberg et Sneidermann
Une remarque pour commencer : dans le cas de conditions composées, les parenthèses jouent un rôle fondamental.Variables A, B, C, D, E en Booléen
Variable X en Entier
Début
Lire X
A ← X > 12
B ← X > 2
C ← X < 6
D ← (A ET B) OU C
E ← A ET (B OU C)
Ecrire D, E
FinSi X = 3, alors on remarque que D sera VRAI alors que E sera FAUX.S’il n’y a dans une condition que des ET, ou que des OU, en revanche, les parenthèses ne changent strictement rien.Dans une condition composée employant à la fois des opérateurs ET et des opérateurs OU, la présence de parenthèses possède une influence sur le résultat, tout comme dans le cas d’une expression numérique comportant des multiplications et des additions.On en arrive à une autre propriété des ET et des OU, bien plus intéressante.Spontanément, on pense souvent que ET et OU s’excluent mutuellement, au sens où un problème donné s’exprime soit avec un ET, soit avec un OU. Pourtant, ce n’est pas si évident.Quand faut-il ouvrir la fenêtre de la salle ? Uniquement si les conditions l’imposent, à savoir :Si il fait trop chaud ET il ne pleut pas Alors
Ouvrir la fenêtre
Sinon
Fermer la fenêtre
FinsiCette petite règle pourrait tout aussi bien être formulée comme suit :Si il ne fait pas trop chaud OU il pleut Alors
Fermer la fenêtre
Sinon
Ouvrir la fenêtre
FinsiCes deux formulations sont strictement équivalentes. Ce qui nous amène à la conclusion suivante :Toute structure de test requérant une condition composée faisant intervenir l’opérateur ET peut être exprimée de manière équivalente avec un opérateur OU, et réciproquement.Ceci est moins surprenant qu’il n’y paraît au premier abord. Jetez pour vous en convaincre un œil sur les tables de vérité, et vous noterez la symétrie entre celle du ET et celle du OU. Dans les deux tables, il y a trois cas sur quatre qui mènent à un résultat, et un sur quatre qui mène au résultat inverse. Alors, rien d’étonnant à ce qu’une situation qui s’exprime avec une des tables (un des opérateurs logiques) puisse tout aussi bien être exprimée avec l’autre table (l’autre opérateur logique). Toute l’astuce consiste à savoir effectuer correctement ce passage.Bien sûr, on ne peut pas se contenter de remplacer purement et simplement les ET par des OU ; ce serait un peu facile. La règle d’équivalence est la suivante (on peut la vérifier sur l’exemple de la fenêtre) :Si A ET B Alors
Instructions 1
Sinon
Instructions 2
Finsi
équivaut à :
Si NON A OU NON B Alors
Instructions 2
Sinon
Instructions 1
Finsi
Cette règle porte le nom de transformation de Morgan, du nom du mathématicien anglais qui l'a formulée.
Ce titre un peu provocateur (mais néanmoins justifié) a pour but d’attirer maintenant votre attention sur un fait fondamental en algorithmique, fait que plusieurs remarques précédentes ont déjà dû vous faire soupçonner : il n’y a jamais une seule manière juste de traiter les structures alternatives. Et plus généralement, il n’y a jamais une seule manière juste de traiter un problème. Entre les différentes possibilités, qui ne sont parfois pas meilleures les unes que les autres, le choix est une affaire de style.C’est pour cela qu’avec l’habitude, on reconnaît le style d’un programmeur aussi sûrement que s’il s’agissait de style littéraire.Reprenons nos opérateurs de comparaison maintenant familiers, le ET et le OU. En fait, on s’aperçoit que l’on pourrait tout à fait s’en passer ! Par exemple, pour reprendre l’exemple de la fenêtre de la salle :Si il fait trop chaud ET il ne pleut pas Alors
Ouvrir la fenêtre
Sinon
Fermer la fenêtre
FinsiPossède un parfait équivalent algorithmique sous la forme de :Si il fait trop chaud Alors
Si il ne pleut pas Alors
Ouvrir la fenêtre
Sinon
Fermer la fenêtre
Finsi
Sinon
Fermer la fenêtre
FinsiDans cette dernière formulation, nous n’avons plus recours à une condition composée (mais au prix d’un test imbriqué supplémentaire)Et comme tout ce qui s’exprime par un ET peut aussi être exprimé par un OU, nous en concluons que le OU peut également être remplacé par un test imbriqué supplémentaire. On peut ainsi poser cette règle stylistique générale :Dans une structure alternative complexe, les conditions composées, l’imbrication des structures de tests et l’emploi des variables booléennes ouvrent la possibilité de choix stylistiques différents. L’alourdissement des conditions allège les structures de tests et le nombre des booléens nécessaires ; l’emploi de booléens supplémentaires permet d’alléger les conditions et les structures de tests, et ainsi de suite.Si vous avez compris ce qui précède, et que l'exercice de la date ne vous pose plus aucun problème, alors vous savez tout ce qu'il y a à savoir sur les tests pour affronter n'importe quelle situation. Non, ce n'est pas de la démagogie !Malheureusement, nous ne sommes pas tout à fait au bout de nos peines ; il reste une dernière structure logique à examiner, et pas des moindres… votre commentaire
-
Partie 3
Les Tests« Il est assez difficile de trouver une erreur dans son code quand on la cherche. C’est encore bien plus dur quand on est convaincu que le code est juste. » - Steve McConnell
« Il n’existe pas, et il n’existera jamais, de langage dans lequel il soit un tant soit peu difficile d’écrire de mauvais programmes ». - Anonyme
« Si le déboguage est l’art d’enlever les bogues, alors la programmation doit être l’art de les créer. » - Anonyme
Je vous avais dit que l’algorithmique, c’est la combinaison de quatre structures élémentaires. Nous en avons déjà vu deux, voici la troisième. Autrement dit, on a quasiment fini le programme.Mais non, je rigole.Reprenons le cas de notre « programmation algorithmique du touriste égaré ». Normalement, l’algorithme ressemblera à quelque chose comme : « Allez tout droit jusqu’au prochain carrefour, puis prenez à droite et ensuite la deuxième à gauche, et vous y êtes ».Mais en cas de doute légitime de votre part, cela pourrait devenir : « Allez tout droit jusqu’au prochain carrefour et là regardez à droite. Si la rue est autorisée à la circulation, alors prenez la et ensuite c’est la deuxième à gauche. Mais si en revanche elle est en sens interdit, alors continuez jusqu’à la prochaine à droite, prenez celle-là, et ensuite la première à droite ».Ce deuxième algorithme a ceci de supérieur au premier qu’il prévoit, en fonction d’une situation pouvant se présenter de deux façons différentes, deux façons différentes d’agir. Cela suppose que l’interlocuteur (le touriste) sache analyser la condition que nous avons fixée à son comportement (« la rue est-elle en sens interdit ? ») pour effectuer la série d’actions correspondante.Eh bien, croyez le ou non, mais les ordinateurs possèdent cette aptitude, sans laquelle d’ailleurs nous aurions bien du mal à les programmer. Nous allons donc pouvoir parler à notre ordinateur comme à notre touriste, et lui donner des séries d’instructions à effectuer selon que la situation se présente d’une manière ou d’une autre. Cette structure logique répond au doux nom de test. Toutefois, ceux qui tiennent absolument à briller en société parleront également de structure alternative.Il n’y a que deux formes possibles pour un test ; la première est la plus simple, la seconde la plus complexe.Si booléen Alors
Instructions
FinsiSi booléen Alors
Instructions 1
Sinon
Instructions 2
FinsiCeci appelle quelques explications.Un booléen est une expression dont la valeur est VRAI ou FAUX. Cela peut donc être (il n’y a que deux possibilités) :- une variable (ou une expression) de type booléen
- une condition
Nous reviendrons dans quelques instants sur ce qu’est une condition en informatique.Toujours est-il que la structure d’un test est relativement claire. Dans la forme la plus simple, arrivé à la première ligne (Si… Alors) la machine examine la valeur du booléen. Si ce booléen a pour valeur VRAI, elle exécute la série d’instructions. Cette série d’instructions peut être très brève comme très longue, cela n’a aucune importance. En revanche, dans le cas où le booléen est faux, l'ordinateur saute directement aux instructions situées après le FinSi.Dans le cas de la structure complète, c'est à peine plus compliqué. Dans le cas où le booléen est VRAI, et après avoir exécuté la série d'instructions 1, au moment où elle arrive au mot « Sinon », la machine saute directement à la première instruction située après le « Finsi ». De même, au cas où le booléen a comme valeur « Faux », la machine saute directement à la première ligne située après le « Sinon » et exécute l’ensemble des « instructions 2 ». Dans tous les cas, les instructions situées juste après le FinSi seront exécutées normalement.En fait, la forme simplifiée correspond au cas où l’une des deux « branches » du Si est vide. Dès lors, plutôt qu’écrire « sinon ne rien faire du tout », il est plus simple de ne rien écrire. Et laisser un Si... complet, avec une des deux branches vides, est considéré comme une très grosse maladresse pour un programmeur, même si cela ne constitue pas à proprement parler une faute.Exprimé sous forme de pseudo-code, la programmation de notre touriste de tout à l’heure donnerait donc quelque chose du genre :Allez tout droit jusqu’au prochain carrefour
Si la rue à droite est autorisée à la circulation Alors
Tournez à droite
Avancez
Prenez la deuxième à gauche
Sinon
Continuez jusqu’à la prochaine rue à droite
Prenez cette rue
Prenez la première à droite
FinsiUne condition est une comparaisonCette définition est essentielle ! Elle signifie qu’une condition est composée de trois éléments :- une valeur
- un opérateur de comparaison
- une autre valeur
Les valeurs peuvent être a priori de n’importe quel type (numériques, caractères…). Mais si l’on veut que la comparaison ait un sens, il faut que les deux valeurs de la comparaison soient du même type !Les opérateurs de comparaison sont :- égal à…
- différent de…
- strictement plus petit que…
- strictement plus grand que…
- plus petit ou égal à…
- plus grand ou égal à…
L’ensemble des trois éléments constituant la condition constitue donc, si l’on veut, une affirmation, qui a un moment donné est VRAIE ou FAUSSE.A noter que ces opérateurs de comparaison peuvent tout à fait s’employer avec des caractères. Ceux-ci sont codés par la machine dans l’ordre alphabétique (rappelez vous le code ASCII vu dans le préambule), les majuscules étant systématiquement placées avant les minuscules. Ainsi on a :“t” < “w” VRAI
“Maman” > “Papa“ FAUX
“maman” > “Papa” VRAIRemarque très importante
En formulant une condition dans un algorithme, il faut se méfier comme de la peste de certains raccourcis du langage courant, ou de certaines notations valides en mathématiques, mais qui mènent à des non-sens informatiques. Prenons par exemple la phrase « Toto est compris entre 5 et 8 ». On peut être tenté de la traduire par : 5 < Toto < 8
Or, une telle expression, qui a du sens en français, comme en mathématiques, ne veut rien dire en programmation. En effet, elle comprend deux opérateurs de comparaison, soit un de trop, et trois valeurs, soit là aussi une de trop. On va voir dans un instant comment traduire convenablement une telle condition.
Certains problèmes exigent parfois de formuler des conditions qui ne peuvent pas être exprimées sous la forme simple exposée ci-dessus. Reprenons le cas « Toto est inclus entre 5 et 8 ». En fait cette phrase cache non une, mais deux conditions. Car elle revient à dire que « Toto est supérieur à 5 et Toto est inférieur à 8 ». Il y a donc bien là deux conditions, reliées par ce qu’on appelle un opérateur logique, le mot ET.Comme on l’a évoqué plus haut, l’informatique met à notre disposition quatre opérateurs logiques : ET, OU, NON, et XOR.- Le ET a le même sens en informatique que dans le langage courant. Pour que "Condition1 ET Condition2" soit VRAI, il faut impérativement que Condition1 soit VRAI et que Condition2 soit VRAI. Dans tous les autres cas, "Condition 1 et Condition2" sera faux.
- Il faut se méfier un peu plus du OU. Pour que "Condition1 OU Condition2" soit VRAI, il suffit que Condition1 soit VRAIE ou que Condition2 soit VRAIE. Le point important est que si Condition1 est VRAIE et que Condition2 est VRAIE aussi, Condition1 OU Condition2 reste VRAIE. Le OU informatique ne veut donc pas dire « ou bien »
- Le XOR (ou OU exclusif) fonctionne de la manière suivante. Pour que "Condition1 XOR Condition2" soit VRAI, il faut que soit Condition1 soit VRAI, soit que Condition2 soit VRAI. Si toutes les deux sont fausses, ou que toutes les deux sont VRAI, alors le résultat global est considéré comme FAUX. Le XOR est donc l'équivalent du "ou bien" du langage courant.
J’insiste toutefois sur le fait que le XOR est une rareté, dont il n’est pas strictement indispensable de s’encombrer en programmation. - Enfin, le NON inverse une condition : NON(Condition1)est VRAI si Condition1 est FAUX, et il sera FAUX si Condition1 est VRAI. C'est l'équivalent pour les booléens du signe "moins" que l'on place devant les nombres.
Alors, vous vous demandez peut-être à quoi sert ce NON. Après tout, plutôt qu’écrire NON(Prix > 20), il serait plus simple d’écrire tout bonnement Prix=<20. Dans ce cas précis, c’est évident qu’on se complique inutilement la vie avec le NON. Mais si le NON n'est jamais indispensable, il y a tout de même des situations dans lesquelles il s'avère bien utile.
On représente fréquemment tout ceci dans des tables de vérité (C1 et C2 représentent deux conditions, et on envisage à chaque fois les quatre cas possibles)
C1 et C2 C2 Vrai C2 Faux C1 Vrai Vrai Faux C1 Faux Faux Faux
C1 ou C2 C2 Vrai C2 Faux C1 Vrai Vrai Vrai C1 Faux Vrai Faux
C1 xor C2 C2 Vrai C2 Faux C1 Vrai Faux Vrai C1 Faux Vrai Faux
Non C1 C1 Vrai Faux C1 Faux Vrai LE GAG DE LA JOURNÉE...
...Consiste à formuler dans un test une condition qui ne pourra jamais être vraie, ou jamais être fausse. Si ce n’est pas fait exprès, c’est assez rigolo. Si c’est fait exprès, c’est encore plus drôle, car une condition dont on sait d’avance qu’elle sera toujours fausse n’est pas une condition. Dans tous les cas, cela veut dire qu’on a écrit un test qui n’en est pas un, et qui fonctionne comme s’il n’y en avait pas.
Cela peut être par exemple : Si Toto < 10 ET Toto > 15 Alors… (il est très difficile de trouver un nombre qui soit à la fois inférieur à 10 et supérieur à 15 !)
Bon, ça, c’est un motif immédiat pour payer une tournée générale, et je sens qu’on ne restera pas longtemps le gosier sec.
Graphiquement, on peut très facilement représenter un SI comme un aiguillage de chemin de fer (ou un aiguillage de train électrique, c’est moins lourd à porter). Un SI ouvre donc deux voies, correspondant à deux traitements différents. Mais il y a des tas de situations où deux voies ne suffisent pas. Par exemple, un programme devant donner l’état de l’eau selon sa température doit pouvoir choisir entre trois réponses possibles (solide, liquide ou gazeuse).Une première solution serait la suivante :Variable Temp en Entier
Début
Ecrire "Entrez la température de l’eau :"
Lire Temp
Si Temp =< 0 Alors
Ecrire "C’est de la glace"
FinSi
Si Temp > 0 Et Temp < 100 Alors
Ecrire "C’est du liquide"
Finsi
Si Temp > 100 Alors
Ecrire "C’est de la vapeur"
Finsi
FinVous constaterez que c’est un peu laborieux. Les conditions se ressemblent plus ou moins, et surtout on oblige la machine à examiner trois tests successifs alors que tous portent sur une même chose, la température de l'eau (la valeur de la variable Temp). Il serait ainsi bien plus rationnel d’imbriquer les tests de cette manière :Variable Temp en Entier
Début
Ecrire "Entrez la température de l’eau :"
Lire Temp
Si Temp =< 0 Alors
Ecrire "C’est de la glace"
Sinon
Si Temp < 100 Alors
Ecrire "C’est du liquide"
Sinon
Ecrire "C’est de la vapeur"
Finsi
Finsi
FinNous avons fait des économies : au lieu de devoir taper trois conditions, dont une composée, nous n’avons plus que deux conditions simples. Mais aussi, et surtout, nous avons fait des économies sur le temps d’exécution de l’ordinateur. Si la température est inférieure à zéro, celui-ci écrit dorénavant « C’est de la glace » et passe directement à la fin, sans être ralenti par l’examen d’autres possibilités (qui sont forcément fausses).Cette deuxième version n’est donc pas seulement plus simple à écrire et plus lisible, elle est également plus performante à l’exécution.Les structures de tests imbriqués sont donc un outil indispensable à la simplification et à l’optimisation des algorithmes.
« J'ai l'âme ferroviaire : je regarde passer les vaches » (Léo Ferré)Cette citation n’apporte peut-être pas grand chose à cet exposé, mais je l’aime bien, alors c’était le moment ou jamais.En effet, dans un programme, une structure SI peut être facilement comparée à un aiguillage de train. La voie principale se sépare en deux, le train devant rouler ou sur l’une, ou sur l’autre, et les deux voies se rejoignant tôt ou tard pour ne plus en former qu’une seule, lors du FinSi. On peut schématiser cela ainsi :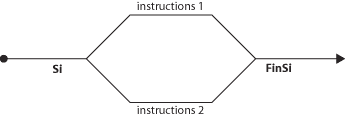 Mais dans certains cas, ce ne sont pas deux voies qu’il nous faut, mais trois, ou même plus. Dans le cas de l’état de l’eau, il nous faut trois voies pour notre « train », puisque l’eau peut être solide, liquide ou gazeuse. Alors, nous n’avons pas eu le choix : pour deux voies, il nous fallait un aiguillage, pour trois voies il nous en faut deux, imbriqués l’un dans l’autre.Cette structure (telle que nous l’avons programmée à la page précédente) devrait être schématisée comme suit :
Mais dans certains cas, ce ne sont pas deux voies qu’il nous faut, mais trois, ou même plus. Dans le cas de l’état de l’eau, il nous faut trois voies pour notre « train », puisque l’eau peut être solide, liquide ou gazeuse. Alors, nous n’avons pas eu le choix : pour deux voies, il nous fallait un aiguillage, pour trois voies il nous en faut deux, imbriqués l’un dans l’autre.Cette structure (telle que nous l’avons programmée à la page précédente) devrait être schématisée comme suit :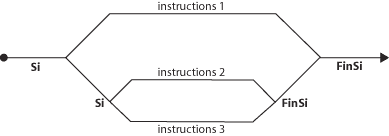 Soyons bien clairs : cette structure est la seule possible du point de vue logique (même si on peut toujours mettre le bas en haut et le haut en bas). Mais du point de vue de l’écriture, le pseudo-code algorithmique admet une simplification supplémentaire. Ainsi, il est possible (mais non obligatoire, que l’algorithme initial :Variable Temp en Entier
Soyons bien clairs : cette structure est la seule possible du point de vue logique (même si on peut toujours mettre le bas en haut et le haut en bas). Mais du point de vue de l’écriture, le pseudo-code algorithmique admet une simplification supplémentaire. Ainsi, il est possible (mais non obligatoire, que l’algorithme initial :Variable Temp en Entier
Début
Ecrire "Entrez la température de l’eau :"
Lire Temp
Si Temp =< 0 Alors
Ecrire "C'est de la glace"
Sinon
Si Temp < 100 Alors
Ecrire "C’est du liquide"
Sinon
Ecrire "C’est de la vapeur"
Finsi
Finsi
Findevienne :Variable Temp en Entier
Début
Ecrire "Entrez la température de l’eau :"
Lire Temp
Si Temp =< 0 Alors
Ecrire "C’est de la glace"
SinonSi Temp < 100 Alors
Ecrire "C’est du liquide"
Sinon
Ecrire "C’est de la vapeur"
Finsi
FinDans le cas de tests imbriqués, le Sinon et le Si peuvent être fusionnés en un SinonSi. On considère alors qu’il s’agit d’un seul bloc de test, conclu par un seul FinSiLe SinonSi permet en quelque sorte de créer (en réalité, de simuler) des aiguillages à plus de deux branches. On peut ainsi enchaîner les SinonSi les uns derrière les autres pour simuler un aiguillage à autant de branches que l’on souhaite.Jusqu’ici, pour écrire nos des tests, nous avons utilisé uniquement des conditions. Mais vous vous rappelez qu’il existe un type de variables (les booléennes) susceptibles de stocker les valeurs VRAI ou FAUX. En fait, on peut donc entrer des conditions dans ces variables, et tester ensuite la valeur de ces variables.Reprenons l’exemple de l’eau. On pourrait le réécrire ainsi :Variable Temp en Entier
Variables A, B en Booléen
Début
Ecrire "Entrez la température de l’eau :"
Lire Temp
A ← Temp =< 0
B ← Temp < 100
Si A Alors
Ecrire "C’est de la glace"
SinonSi B Alors
Ecrire "C’est du liquide"
Sinon
Ecrire "C’est de la vapeur"
Finsi
FinA priori, cette technique ne présente guère d’intérêt : on a alourdi plutôt qu’allégé l’algorithme de départ, en ayant recours à deux variables supplémentaires.- Mais souvenons-nous : une variable booléenne n’a besoin que d’un seul bit pour être stockée. De ce point de vue, l’alourdissement n’est donc pas considérable.
- dans certains cas, notamment celui de conditions composées très lourdes (avec plein de ET et de OU tout partout) cette technique peut faciliter le travail du programmeur, en améliorant nettement la lisibilité de l’algorithme. Les variables booléennes peuvent également s’avérer très utiles pour servir de flag, technique dont on reparlera plus loin (rassurez-vous, rien à voir avec le flagrant délit des policiers).
votre commentaire
-
Partie 1
Les Variables« N’attribuez jamais à la malveillance ce qui s’explique très bien par l’incompétence. » - Napoléon Bonaparte
« A l’origine de toute erreur attribuée à l’ordinateur, vous trouverez au moins deux erreurs humaines. Dont celle consistant à attribuer l’erreur à l’ordinateur. » - Anonyme
Dans un programme informatique, on va avoir en permanence besoin de stocker provisoirement des valeurs. Il peut s’agir de données issues du disque dur, fournies par l’utilisateur (frappées au clavier), ou que sais-je encore. Il peut aussi s’agir de résultats obtenus par le programme, intermédiaires ou définitifs. Ces données peuvent être de plusieurs types (on en reparlera) : elles peuvent être des nombres, du texte, etc. Toujours est-il que dès que l’on a besoin de stocker une information au cours d’un programme, on utilise une variable.Pour employer une image, une variable est une boîte, que le programme (l’ordinateur) va repérer par une étiquette. Pour avoir accès au contenu de la boîte, il suffit de la désigner par son étiquette.En réalité, dans la mémoire vive de l’ordinateur, il n’y a bien sûr pas une vraie boîte, et pas davantage de vraie étiquette collée dessus (j’avais bien prévenu que la boîte et l’étiquette, c’était une image). Dans l’ordinateur, physiquement, il y a un emplacement de mémoire, repéré par une adresse binaire. Si on programmait dans un langage directement compréhensible par la machine, on devrait se fader de désigner nos données par de superbes 10011001 et autres 01001001 (enchanté !). Mauvaise nouvelle : de tels langages existent ! Ils portent le doux nom d’assembleur. Bonne nouvelle : ce ne sont pas les seuls langages disponibles.Les langages informatiques plus évolués (ce sont ceux que presque tout le monde emploie) se chargent précisément, entre autres rôles, d’épargner au programmeur la gestion fastidieuse des emplacements mémoire et de leurs adresses. Et, comme vous commencez à le comprendre, il est beaucoup plus facile d’employer les étiquettes de son choix, que de devoir manier des adresses binaires.La première chose à faire avant de pouvoir utiliser une variable est de créer la boîte et de lui coller une étiquette. Ceci se fait tout au début de l’algorithme, avant même les instructions proprement dites. C’est ce qu’on appelle la déclaration des variables. C’est un genre de déclaration certes moins romantique qu’une déclaration d’amour, mais d’un autre côté moins désagréable qu’une déclaration d’impôts.Le nom de la variable (l’étiquette de la boîte) obéit à des impératifs changeant selon les langages. Toutefois, une règle absolue est qu’un nom de variable peut comporter des lettres et des chiffres, mais qu’il exclut la plupart des signes de ponctuation, en particulier les espaces. Un nom de variable correct commence également impérativement par une lettre. Quant au nombre maximal de signes pour un nom de variable, il dépend du langage utilisé.En pseudo-code algorithmique, on est bien sûr libre du nombre de signes pour un nom de variable, même si pour des raisons purement pratiques, et au grand désespoir de Stéphane Bern, on évite généralement les noms à rallonge.Lorsqu’on déclare une variable, il ne suffit pas de créer une boîte (réserver un emplacement mémoire) ; encore doit-on préciser ce que l’on voudra mettre dedans, car de cela dépendent la taille de la boîte (de l’emplacement mémoire) et le type de codage utilisé.
2.1 Types numériques classiquesCommençons par le cas très fréquent, celui d’une variable destinée à recevoir des nombres.Si l’on réserve un octet pour coder un nombre, je rappelle pour ceux qui dormaient en lisant le chapitre précédent qu’on ne pourra coder que 28 = 256 valeurs différentes. Cela peut signifier par exemple les nombres entiers de 1 à 256, ou de 0 à 255, ou de –127 à +128… Si l’on réserve deux octets, on a droit à 65 536 valeurs ; avec trois octets, 16 777 216, etc. Et là se pose un autre problème : ce codage doit-il représenter des nombres décimaux ? des nombres négatifs ?Bref, le type de codage (autrement dit, le type de variable) choisi pour un nombre va déterminer :- les valeurs maximales et minimales des nombres pouvant être stockés dans la variable
- la précision de ces nombres (dans le cas de nombres décimaux).
Tous les langages, quels qu’ils soient offrent un « bouquet » de types numériques, dont le détail est susceptible de varier légèrement d’un langage à l’autre. Grosso modo, on retrouve cependant les types suivants :
Type Numérique Plage Byte (octet) 0 à 255 Entier simple -32 768 à 32 767 Entier long -2 147 483 648 à 2 147 483 647 Réel simple -3,40x1038 à -1,40x1045 pour les valeurs négatives
1,40x10-45 à 3,40x1038 pour les valeurs positivesRéel double 1,79x10308 à -4,94x10-324 pour les valeurs négatives
4,94x10-324 à 1,79x10308 pour les valeurs positivesPourquoi ne pas déclarer toutes les variables numériques en réel double, histoire de bétonner et d’être certain qu’il n’y aura pas de problème ? En vertu du principe de l’économie de moyens. Un bon algorithme ne se contente pas de « marcher » ; il marche en évitant de gaspiller les ressources de la machine. Sur certains programmes de grande taille, l’abus de variables surdimensionnées peut entraîner des ralentissements notables à l’exécution, voire un plantage pur et simple de l’ordinateur. Alors, autant prendre dès le début de bonnes habitudes d’hygiène.En algorithmique, on ne se tracassera pas trop avec les sous-types de variables numériques (sachant qu'on aura toujours assez de soucis comme ça, allez). On se contentera donc de préciser qu'il s'agit d'un nombre, en gardant en tête que dans un vrai langage, il faudra être plus précis.En pseudo-code, une déclaration de variables aura ainsi cette tête :Variable g en Numérique
ou encore
Variables PrixHT, TauxTVA, PrixTTC en Numérique2.2 Autres types numériquesCertains langages autorisent d’autres types numériques, notamment :- le type monétaire (avec strictement deux chiffres après la virgule)
- le type date (jour/mois/année).
Nous n’emploierons pas ces types dans ce cours ; mais je les signale, car vous ne manquerez pas de les rencontrer en programmation proprement dite.
2.3 Type alphanumériqueFort heureusement, les boîtes que sont les variables peuvent contenir bien d’autres informations que des nombres. Sans cela, on serait un peu embêté dès que l’on devrait stocker un nom de famille, par exemple.On dispose donc également du type alphanumérique (également appelé type caractère, type chaîne ou en anglais, le type string – mais ne fantasmez pas trop vite, les string, c’est loin d’être aussi excitant que le nom le suggère. Une étudiante qui se reconnaîtra si elle lit ces lignes a d'ailleurs mis le doigt - si j'ose m'exprimer ainsi - sur le fait qu'il en va de même en ce qui concerne les bytes).Dans une variable de ce type, on stocke des caractères, qu’il s’agisse de lettres, de signes de ponctuation, d’espaces, ou même de chiffres. Le nombre maximal de caractères pouvant être stockés dans une seule variable string dépend du langage utilisé.Un groupe de caractères (y compris un groupe de un, ou de zéro caractères), qu’il soit ou non stocké dans une variable, d’ailleurs, est donc souvent appelé chaîne de caractères.En pseudo-code, une chaîne de caractères est toujours notée entre guillemetsPourquoi diable ? Pour éviter deux sources principales de possibles confusions :- la confusion entre des nombres et des suites de chiffres. Par exemple, 423 peut représenter le nombre 423 (quatre cent vingt-trois), ou la suite de caractères 4, 2, et 3. Et ce n’est pas du tout la même chose ! Avec le premier, on peut faire des calculs, avec le second, point du tout. Dès lors, les guillemets permettent d’éviter toute ambiguïté : s’il n’y en a pas, 423 est quatre cent vingt trois. S’il y en a, "423" représente la suite des chiffres 4, 2, 3.
- …Mais ce n'est pas le pire. L'autre confusion, bien plus grave - et bien plus fréquente – consiste à se mélanger les pinceaux entre le nom d'une variable et son contenu. Pour parler simplement, cela consiste à confondre l'étiquette d'une boîte et ce qu'il y a à l'intérieur… On reviendra sur ce point crucial dans quelques instants.
2.4 Type booléenLe dernier type de variables est le type booléen : on y stocke uniquement les valeurs logiques VRAI et FAUX.On peut représenter ces notions abstraites de VRAI et de FAUX par tout ce qu'on veut : de l'anglais (TRUE et FALSE) ou des nombres (0 et 1). Peu importe. Ce qui compte, c'est de comprendre que le type booléen est très économique en termes de place mémoire occupée, puisque pour stocker une telle information binaire, un seul bit suffit.Le type booléen est très souvent négligé par les programmeurs, à tort.
Il est vrai qu'il n'est pas à proprement parler indispensable, et qu'on pourrait écrire à peu près n’importe quel programme en l'ignorant complètement. Pourtant, si le type booléen est mis à disposition des programmeurs dans tous les langages, ce n'est pas pour rien. Le recours aux variables booléennes s'avère très souvent un puissant instrument de lisibilité des algorithmes : il peut faciliter la vie de celui qui écrit l'algorithme, comme de celui qui le relit pour le corriger.
Alors, maintenant, c'est certain, en algorithmique, il y a une question de style : c'est exactement comme dans le langage courant, il y a plusieurs manières de s'exprimer pour dire sur le fond la même chose. Nous verrons plus loin différents exemples de variations stylistiques autour d'une même solution. En attendant, vous êtes prévenus : l'auteur de ce cours est un adepte fervent (mais pas irraisonné) de l'utilisation des variables booléennes.3.1 Syntaxe et significationOuf, après tout ce baratin préliminaire, on aborde enfin nos premières véritables manipulations d’algorithmique. Pas trop tôt, certes, mais pas moyen de faire autrement !En fait, la variable (la boîte) n'est pas un outil bien sorcier à manipuler. A la différence du couteau suisse ou du superbe robot ménager vendu sur Télé Boutique Achat, on ne peut pas faire trente-six mille choses avec une variable, mais seulement une et une seule.Cette seule chose qu’on puisse faire avec une variable, c’est l’affecter, c’est-à-dire lui attribuer une valeur. Pour poursuivre la superbe métaphore filée déjà employée, on peut remplir la boîte.En pseudo-code, l'instruction d'affectation se note avec le signe ←Ainsi :Toto ← 24Attribue la valeur 24 à la variable Toto.Ceci, soit dit en passant, sous-entend impérativement que Toto soit une variable de type numérique. Si Toto a été défini dans un autre type, il faut bien comprendre que cette instruction provoquera une erreur. C’est un peu comme si, en donnant un ordre à quelqu’un, on accolait un verbe et un complément incompatibles, du genre « Epluchez la casserole ». Même dotée de la meilleure volonté du monde, la ménagère lisant cette phrase ne pourrait qu’interrompre dubitativement sa tâche. Alors, un ordinateur, vous pensez bien…On peut en revanche sans aucun problème attribuer à une variable la valeur d’une autre variable, telle quelle ou modifiée. Par exemple :Tutu ← TotoSignifie que la valeur de Tutu est maintenant celle de Toto.Notez bien que cette instruction n’a en rien modifié la valeur de Toto : une instruction d’affectation ne modifie que ce qui est situé à gauche de la flèche.Tutu ← Toto + 4Si Toto contenait 12, Tutu vaut maintenant 16. De même que précédemment, Toto vaut toujours 12.Tutu ← Tutu + 1Si Tutu valait 6, il vaut maintenant 7. La valeur de Tutu est modifiée, puisque Tutu est la variable située à gauche de la flèche.Pour revenir à présent sur le rôle des guillemets dans les chaînes de caractères et sur la confusion numéro 2 signalée plus haut, comparons maintenant deux algorithmes suivants :Exemple n°1
Début
Riri ← "Loulou"
Fifi ← "Riri"
Fin
Exemple n°2
Début
Riri ← "Loulou"
Fifi ← Riri
FinLa seule différence entre les deux algorithmes consiste dans la présence ou dans l’absence des guillemets lors de la seconde affectation. Et l'on voit que cela change tout !Dans l'exemple n°1, ce que l'on affecte à la variable Fifi, c'est la suite de caractères R – i – r - i. Et à la fin de l’algorithme, le contenu de la variable Fifi est donc « Riri ».Dans l'exemple n°2, en revanche, Riri étant dépourvu de guillemets, n'est pas considéré comme une suite de caractères, mais comme un nom de variable. Le sens de la ligne devient donc : « affecte à la variable Fifi le contenu de la variable Riri ». A la fin de l’algorithme n°2, la valeur de la variable Fifi est donc « Loulou ». Ici, l’oubli des guillemets conduit certes à un résultat, mais à un résultat différent.A noter, car c’est un cas très fréquent, que généralement, lorsqu’on oublie les guillemets lors d’une affectation de chaîne, ce qui se trouve à droite du signe d’affectation ne correspond à aucune variable précédemment déclarée et affectée. Dans ce cas, l’oubli des guillemets se solde immédiatement par une erreur d’exécution.Ceci est une simple illustration. Mais elle résume l’ensemble des problèmes qui surviennent lorsqu’on oublie la règle des guillemets aux chaînes de caractères.
3.2 Ordre des instructionsIl va de soi que l’ordre dans lequel les instructions sont écrites va jouer un rôle essentiel dans le résultat final. Considérons les deux algorithmes suivants :Exemple 1
Variable A en Numérique
Début
A ← 34
A ← 12
Fin
Exemple 2
Variable A en Numérique
Début
A ← 12
A ← 34
FinIl est clair que dans le premier cas la valeur finale de A est 12, dans l’autre elle est 34 .Il est tout aussi clair que ceci ne doit pas nous étonner. Lorsqu’on indique le chemin à quelqu’un, dire « prenez tout droit sur 1km, puis à droite » n’envoie pas les gens au même endroit que si l’on dit « prenez à droite puis tout droit pendant 1 km ».Enfin, il est également clair que si l’on met de côté leur vertu pédagogique, les deux algorithmes ci-dessus sont parfaitement idiots ; à tout le moins ils contiennent une incohérence. Il n’y a aucun intérêt à affecter une variable pour l’affecter différemment juste après. En l’occurrence, on aurait tout aussi bien atteint le même résultat en écrivant simplement :Exemple 1
Variable A en Numérique
Début
A ← 12
Fin
Exemple 2
Variable A en Numérique
Début
A ← 34
FinTous les éléments sont maintenant en votre possession pour que ce soit à vous de jouer !
Si on fait le point, on s’aperçoit que dans une instruction d’affectation, on trouve :- à gauche de la flèche, un nom de variable, et uniquement cela. En ce monde empli de doutes qu’est celui de l’algorithmique, c’est une des rares règles d’or qui marche à tous les coups : si on voit à gauche d’une flèche d’affectation autre chose qu’un nom de variable, on peut être certain à 100% qu’il s’agit d’une erreur.
- à droite de la flèche, ce qu’on appelle une expression. Voilà encore un mot qui est trompeur ; en effet, ce mot existe dans le langage courant, où il revêt bien des significations. Mais en informatique, le terme d’expression ne désigne qu’une seule chose, et qui plus est une chose très précise :
Une expression est un ensemble de valeurs, reliées par des opérateurs, et équivalent à une seule valeurCette définition vous paraît peut-être obscure. Mais réfléchissez-y quelques minutes, et vous verrez qu’elle recouvre quelque chose d’assez simple sur le fond. Par exemple, voyons quelques expressions de type numérique. Ainsi :7
5+4
123-45+844
Toto-12+5-Riri…sont toutes des expressions valides, pour peu que Toto et Riri soient bien des nombres. Car dans le cas contraire, la quatrième expression n’a pas de sens. En l’occurrence, les opérateurs que j’ai employés sont l’addition (+) et la soustraction (-).Revenons pour le moment sur l’affectation. Une condition supplémentaire (en plus des deux précédentes) de validité d’une instruction d’affectation est que :- l’expression située à droite de la flèche soit du même type que la variable située à gauche. C’est très logique : on ne peut pas ranger convenablement des outils dans un sac à provision, ni des légumes dans une trousse à outils… sauf à provoquer un résultat catastrophique.
Si l’un des trois points énumérés ci-dessus n’est pas respecté, la machine sera incapable d’exécuter l’affectation, et déclenchera une erreur (est-il besoin de dire que si aucun de ces points n’est respecté, il y aura aussi erreur !)On va maintenant détailler ce que l’on entend par le terme d’ opérateur.Un opérateur est un signe qui relie deux valeurs, pour produire un résultat.Les opérateurs possibles dépendent du type des valeurs qui sont en jeu. Allons-y, faisons le tour, c’est un peu fastidieux, mais comme dit le sage au petit scarabée, quand c’est fait, c’est plus à faire.
4.1 Opérateurs numériques :Ce sont les quatre opérations arithmétiques tout ce qu’il y a de classique.+ : addition- : soustraction* : multiplication/ : divisionMentionnons également le ^ qui signifie « puissance ». 45 au carré s’écrira donc 45 ^ 2.Enfin, on a le droit d’utiliser les parenthèses, avec les mêmes règles qu’en mathématiques. La multiplication et la division ont « naturellement » priorité sur l’addition et la soustraction. Les parenthèses ne sont ainsi utiles que pour modifier cette priorité naturelle.Cela signifie qu’en informatique, 12 * 3 + 5 et (12 * 3) + 5 valent strictement la même chose, à savoir 41. Pourquoi dès lors se fatiguer à mettre des parenthèses inutiles ?En revanche, 12 * (3 + 5) vaut 12 * 8 soit 96. Rien de difficile là-dedans, que du normal.
4.2 Opérateur alphanumérique : &Cet opérateur permet de concaténer, autrement dit d’agglomérer, deux chaînes de caractères. Par exemple :Variables A, B, C en Caractère
Début
A ← "Gloubi"
B ← "Boulga"
C ← A & B
FinLa valeur de C à la fin de l’algorithme est "GloubiBoulga"
4.3 Opérateurs logiques (ou booléens) :Il s’agit du ET, du OU, du NON et du mystérieux (mais rarissime XOR). Nous les laisserons de côté… provisoirement, soyez-en sûrs.5. Deux remarques pour terminer Maintenant que nous sommes familiers des variables et que nous les manipulons les yeux fermés (mais les neurones en éveil, toutefois), j’attire votre attention sur la trompeuse similitude de vocabulaire entre les mathématiques et l’informatique. En mathématiques, une « variable » est généralement une inconnue, qui recouvre un nombre non précisé de valeurs. Lorsque j’écris :y = 3 x + 2les « variables » x et y satisfaisant à l’équation existent en nombre infini (graphiquement, l’ensemble des solutions à cette équation dessine une droite). Lorsque j’écris :ax² + bx + c = 0la « variable » x désigne les solutions à cette équation, c’est-à-dire zéro, une ou deux valeurs à la fois…En informatique, une variable possède à un moment donné une valeur et une seule. A la rigueur, elle peut ne pas avoir de valeur du tout (une fois qu’elle a été déclarée, et tant qu’on ne l’a pas affectée. A signaler que dans certains langages, les variables non encore affectées sont considérées comme valant automatiquement zéro). Mais ce qui est important, c’est que cette valeur justement, ne « varie » pas à proprement parler. Du moins ne varie-t-elle que lorsqu’elle est l’objet d’une instruction d’affectation.La deuxième remarque concerne le signe de l’affectation. En algorithmique, comme on l’a vu, c’est le signe ←. Mais en pratique, la quasi totalité des langages emploient le signe égal. Et là, pour les débutants, la confusion avec les maths est également facile. En maths, A = B et B = A sont deux propositions strictement équivalentes. En informatique, absolument pas, puisque cela revient à écrire A ← B et B ← A, deux choses bien différentes. De même, A = A + 1, qui en mathématiques, constitue une équation sans solution, représente en programmation une action tout à fait licite (et de surcroît extrêmement courante). Donc, attention ! ! ! La meilleure des vaccinations contre cette confusion consiste à bien employer le signe ← en pseudo-code, signe qui a le mérite de ne pas laisser place à l’ambiguïté. Une fois acquis les bons réflexes avec ce signe, vous n’aurez plus aucune difficulté à passer au = des langages de programmation. votre commentaire
-
Préambule : Le Codage« L’information n’est pas le savoir. Le savoir n’est pas la sagesse. La sagesse n’est pas la beauté. La beauté n’est pas l’amour. L’amour n’est pas la musique, et la musique, c’est ce qu’il y a de mieux. » - Frank Zappa« Les ordinateurs sont comme les dieux de l’Ancien Testament : avec beaucoup de règles, et sans pitié. » - Joseph Campbell« Compter en octal, c’est comme compter en décimal, si on n’utilise pas ses pouces » - Tom Lehrer« Il y a 10 sortes de gens au monde : ceux qui connaissent le binaire et les autres » - Anonyme
C’est bien connu, les ordinateurs sont comme le gros rock qui tâche : ils sont binaires.Mais ce qui est moins connu, c’est ce que ce qualificatif de « binaire » recouvre exactement, et ce qu’il implique. Aussi, avant de nous plonger dans les arcanes de l’algorithmique proprement dite, ferons-nous un détour par la notion de codage binaire. Contrairement aux apparences, nous ne sommes pas éloignés de notre sujet principal. Tout au contraire, ce que nous allons voir à présent constitue un ensemble de notions indispensables à l’écriture de programmes. Car pour parler à une machine, mieux vaut connaître son vocabulaire…De nos jours, les ordinateurs sont ces machines merveilleuses capables de traiter du texte, d’afficher des tableaux de maître, de jouer de la musique ou de projeter des vidéos. On n’en est pas encore tout à fait à HAL, l’ordinateur de 2001 Odyssée de l’Espace, à « l’intelligence » si développée qu’il a peur de mourir… pardon, d’être débranché. Mais l’ordinateur paraît être une machine capable de tout faire.Pourtant, les ordinateurs ont beau sembler repousser toujours plus loin les limites de leur champ d’action, il ne faut pas oublier qu’en réalité, ces fiers-à-bras ne sont toujours capables que d’une seule chose : faire des calculs, et uniquement cela. Eh oui, ces gros malins d’ordinateurs sont restés au fond ce qu’ils ont été depuis leur invention : de vulgaires calculatrices améliorées !Lorsqu’un ordinateur traite du texte, du son, de l’image, de la vidéo, il traite en réalité des nombres. En fait, dire cela, c’est déjà lui faire trop d’honneur. Car même le simple nombre « 3 » reste hors de portée de l’intelligence d’un ordinateur, ce qui le situe largement en dessous de l’attachant chimpanzé Bonobo, qui sait, entre autres choses, faire des blagues à ses congénères et jouer au Pac-Man. Un ordinateur manipule exclusivement des informations binaires, dont on ne peut même pas dire sans être tendancieux qu’il s’agit de nombres.Mais qu’est-ce qu’une information binaire ? C’est une information qui ne peut avoir que deux états : par exemple, ouvert - fermé, libre – occupé, militaire – civil, assis – couché, blanc – noir, vrai – faux, etc. Si l’on pense à des dispositifs physiques permettant de stocker ce genre d’information, on pourrait citer : chargé – non chargé, haut – bas, troué – non troué.Je ne donne pas ces derniers exemples au hasard : ce sont précisément ceux dont se sert un ordinateur pour stocker l’ensemble des informations qu’il va devoir manipuler. En deux mots, la mémoire vive (la « RAM ») est formée de millions de composants électroniques qui peuvent retenir ou relâcher une charge électrique. La surface d’un disque dur, d’une bande ou d’une disquette est recouverte de particules métalliques qui peuvent, grâce à un aimant, être orientées dans un sens ou dans l’autre. Et sur un CD-ROM, on trouve un long sillon étroit irrégulièrement percé de trous.Toutefois, la coutume veut qu’on symbolise une information binaire, quel que soit son support physique, sous la forme de 1 et de 0. Il faut bien comprendre que ce n’est là qu’une représentation, une image commode, que l’on utilise pour parler de toute information binaire. Dans la réalité physique, il n’y a pas plus de 1 et de 0 qui se promènent dans les ordinateurs qu’il n’y a écrit, en lettres géantes, « Océan Atlantique » sur la mer quelque part entre la Bretagne et les Antilles. Le 1 et le 0 dont parlent les informaticiens sont des signes, ni plus, ni moins, pour désigner une information, indépendamment de son support physique.Les informaticiens seraient-ils des gens tordus, possédant un goût immodéré pour l’abstraction, ou pour les jeux intellectuels alambiqués ? Non, pas davantage en tout cas que le reste de leurs contemporains non-informaticiens. En fait, chacun d’entre nous pratique ce genre d’abstraction tous les jours, sans pour autant trouver cela bizarre ou difficile. Simplement, nous le faisons dans la vie quotidienne sans y penser. Et à force de ne pas y penser, nous ne remarquons même plus quel mécanisme subtil d’abstraction est nécessaire pour pratiquer ce sport.Lorsque nous disons que 4+3=7 (ce qui reste, normalement, dans le domaine de compétence mathématique de tous ceux qui lisent ce cours !), nous manions de pures abstractions, représentées par de non moins purs symboles ! Un être humain d’il y a quelques millénaires se serait demandé longtemps qu’est-ce que c’est que « quatre » ou « trois », sans savoir quatre ou trois « quoi ? ». Mine de rien, le fait même de concevoir des nombres, c’est-à-dire de pouvoir considérer, dans un ensemble, la quantité indépendamment de tout le reste, c’est déjà une abstraction très hardie, qui a mis très longtemps avant de s’imposer à tous comme une évidence. Et le fait de faire des additions sans devoir préciser des additions « de quoi ? », est un pas supplémentaire qui a été encore plus difficile à franchir.Le concept de nombre, de quantité pure, a donc constitué un immense progrès (que les ordinateurs n’ont quant à eux, je le répète, toujours pas accompli). Mais si concevoir les nombres, c’est bien, posséder un système de notation performant de ces nombres, c’est encore mieux. Et là aussi, l’humanité a mis un certain temps (et essayé un certain nombre de pistes qui se sont révélées être des impasses) avant de parvenir au système actuel, le plus rationnel. Ceux qui ne sont pas convaincus des progrès réalisés en ce domaine peuvent toujours essayer de résoudre une multiplication comme 587 x 644 en chiffres romains, on leur souhaite bon courage !2. La numérotation de position en base décimaleL’humanité actuelle, pour représenter n’importe quel nombre, utilise un système de numérotation de position, à base décimale. Qu’est-ce qui se cache derrière cet obscur jargon ?Commençons par la numérotation de position. Pour représenter un nombre, aussi grand soit-il, nous disposons d’un alphabet spécialisé : une série de 10 signes qui s’appellent les chiffres. Et lorsque nous écrivons un nombre en mettant certains de ces chiffres les uns derrière les autres, l’ordre dans lequel nous mettons les chiffres est capital. Ainsi, par exemple, 2 569 n’est pas du tout le même nombre que 9 562. Et pourquoi ? Quel opération, quel décodage mental effectuons-nous lorsque nous lisons une suite de chiffres représentant un nombre ? Le problème, c’est que nous sommes tellement habitués à faire ce décodage de façon instinctive que généralement nous n’en connaissons plus les règles. Mais ce n’est pas très compliqué de les reconstituer… Et c’est là que nous mettons le doigt en plein dans la deuxième caractéristique de notre système de notation numérique : son caractère décimal.Lorsque j’écris 9562, de quel nombre est-ce que je parle ? Décomposons la lecture chiffre par chiffre, de gauche à droite :9562, c’est 9000 + 500 + 60 + 2.Allons plus loin, même si cela paraît un peu bébête :-
9000, c’est 9 x 1000, parce que le 9 est le quatrième chiffre en partant de la droite
-
500, c’est 5 x 100, parce que le 5 est le troisième chiffre en partant de la droite
-
60, c’est 6 x 10, parce que le 6 est le deuxième chiffre en partant de la droite
-
2, c’est 2 x 1, parce que le 2 est le premier chiffre en partant de la droite
On peut encore écrire ce même nombre d’une manière légèrement différente. Au lieu de :9 562 = 9 x 1 000 + 5 x 100 + 6 x 10 + 2,On écrit que :9 562 = (9 x 10 x 10 x 10) + (5 x 10 x 10) + (6 x 10) + (2)Arrivés à ce stade de la compétition, je prie les allergiques de m’excuser, mais il nous faut employer un petit peu de jargon mathématique. Ce n’est pas grand-chose, et on touche au but. Alors, courage ! En fait, ce jargon se résume au fait que les matheux notent la ligne ci-dessus à l’aide du symbole de « puissance ». Cela donne :9 562 = 9 x 103 + 5 x 102 + 6 x 101 + 2 x 100Et voilà, nous y sommes. Nous avons dégagé le mécanisme général de la représentation par numérotation de position en base décimale.Alors, nous en savons assez pour conclure sur les conséquences du choix de la base décimale. Il y en a deux, qui n’en forment en fin de compte qu’une seule :-
parce que nous sommes en base décimale, nous utilisons un alphabet numérique de dix symboles. Nous nous servons de dix chiffres, pas un de plus, pas un de moins.
-
toujours parce nous sommes en base décimale, la position d’un de ces dix chiffres dans un nombre désigne la puissance de dix par laquelle ce chiffre doit être multiplié pour reconstituer le nombre. Si je trouve un 7 en cinquième position à partir de la droite, ce 7 ne représente pas 7 mais 7 fois 104, soit 70 000.
Un dernier mot concernant le choix de la base dix. Pourquoi celle-là et pas une autre ? Après tout, la base dix n’était pas le seul choix possible. Les babyloniens, qui furent de brillants mathématiciens, avaient en leur temps adopté la base 60 (dite sexagésimale). Cette base 60 impliquait certes d’utiliser un assez lourd alphabet numérique de 60 chiffres. Mais c’était somme toute un inconvénient mineur, et en retour, elle possédait certains avantages non négligeables. 60 étant un nombre divisible par beaucoup d’autres (c’est pour cette raison qu’il avait été choisi), on pouvait, rien qu’en regardant le dernier chiffre, savoir si un nombre était divisible par 2, 3, 4, 5, 6, 10, 12, 15, 20 et 30. Alors qu’en base 10, nous ne pouvons immédiatement répondre à la même question que pour les diviseurs 2 et 5. La base sexagésimale a certes disparu en tant que système de notation des nombres. Mais Babylone nous a laissé en héritage sa base sexagésimale dans la division du cercle en soixante parties (pour compter le temps en minutes et secondes), et celle en 6 x 60 parties (pour les degrés de la géométrie et de l’astronomie).Alors, pourquoi avons-nous adopté la base décimale, moins pratique à bien des égards ? Nul doute que cela tienne au dispositif matériel grâce auquel tout être humain normalement constitué stocke spontanément une information numérique : ses doigts !Profitons-en pour remarquer que le professeur Shadoko avait inventé exactement le même système, la seule différence étant qu'il avait choisi la base 4 (normal, les shadoks n'avaient que 4 mots). Regardez donc cette video - ou comment faire rigoler les gens en ne disant (presque) que des choses vraies :
J'ajoute que c'est l'ensemble des videos des shadoks, et en particulier celles traitant de la logique et des mathématiques, qui vaut son pesant de cacahuètes interstellaires. Mais hélas cela nous éloignerait un peu trop de notre propos (c'est pas grave, on y reviendra à la prochaine pause).
3. La numérotation de position en base binaireLes ordinateurs, eux, comme on l’a vu, ont un dispositif physique fait pour stocker (de multiples façons) des informations binaires. Alors, lorsqu’on représente une information stockée par un ordinateur, le plus simple est d’utiliser un système de représentation à deux chiffres : les fameux 0 et 1. Mais une fois de plus, je me permets d’insister, le choix du 0 et du 1 est une pure convention, et on aurait pu choisir n’importe quelle autre paire de symboles à leur place.Dans un ordinateur, le dispositif qui permet de stocker de l’information est donc rudimentaire, bien plus rudimentaire que les mains humaines. Avec des mains humaines, on peut coder dix choses différentes (en fait bien plus, si l’on fait des acrobaties avec ses doigts, mais écartons ce cas). Avec un emplacement d’information d’ordinateur, on est limité à deux choses différentes seulement. Avec une telle information binaire, on ne va pas loin. Voilà pourquoi, dès leur invention, les ordinateurs ont été conçus pour manier ces informations par paquets de 0 et de 1. Et la taille de ces paquets a été fixée à 8 informations binaires.Une information binaire (symbolisée couramment par 0 ou 1) s’appelle un bit (en anglais... bit).
Un groupe de huit bits s’appelle un octet (en anglais, byte)
Donc, méfiance avec le byte (en abrégé, B majuscule), qui vaut un octet, c'est-à-dire huit bits (en abrégé, b minuscule).Dans combien d’états différents un octet peut-il se trouver ? Le calcul est assez facile (mais il faut néanmoins savoir le refaire). Chaque bit de l’octet peut occuper deux états. Il y a donc dans un octet :2 x 2 x 2 x 2 x 2 x 2 x 2 x 2 = 28 = 256 possibilitésCela signifie qu’un octet peut servir à coder 256 nombres différents : ce peut être la série des nombres entiers de 1 à 256, ou de 0 à 255, ou de –127 à +128. C’est une pure affaire de convention, de choix de codage. Mais ce qui n’est pas affaire de choix, c’est le nombre de possibilités : elles sont 256, pas une de plus, pas une de moins, à cause de ce qu’est, par définition, un octet.Si l’on veut coder des nombres plus grands que 256, ou des nombres négatifs, ou des nombres décimaux, on va donc être contraint de mobiliser plus d’un octet. Ce n’est pas un problème, et c’est très souvent que les ordinateurs procèdent ainsi.En effet, avec deux octets, on a 256 x 256 = 65 536 possibilités.En utilisant trois octets, on passe à 256 x 256 x 256 = 16 777 216 possibilités.Et ainsi de suite, je ne m’attarderai pas davantage sur les différentes manières de coder les nombres avec des octets. On abordera de nouveau brièvement le sujet un peu plus loin.Cela implique également qu’un octet peut servir à coder autre chose qu’un nombre : l’octet est très souvent employé pour coder du texte. Il y a 26 lettres dans l’alphabet. Même en comptant différemment les minuscules et les majuscules, et même en y ajoutant les chiffres et les signes de ponctuation, on arrive à un total inférieur à 256. Cela veut dire que pour coder convenablement un texte, le choix d’un caractère par octet est un choix pertinent.Se pose alors le problème de savoir quel caractère doit être représenté par quel état de l’octet. Si ce choix était librement laissé à chaque informaticien, ou à chaque fabricant d’ordinateur, la communication entre deux ordinateurs serait un véritable casse-tête. L’octet 10001001 serait par exemple traduit par une machine comme un T majuscule, et par une autre comme une parenthèse fermante ! Aussi, il existe un standard international de codage des caractères et des signes de ponctuation. Ce standard stipule quel état de l’octet correspond à quel signe du clavier. Il s’appelle l’ASCII (pour American Standard Code for Information Interchange). Et fort heureusement, l’ASCII est un standard universellement reconnu et appliqué par les fabricants d’ordinateurs et de logiciels. Bien sûr, se pose le problème des signes propres à telle ou telle langue (comme les lettres accentuées en français, par exemple). L’ASCII a paré le problème en réservant certains codes d’octets pour ces caractères spéciaux à chaque langue. En ce qui concerne les langues utilisant un alphabet non latin, un standard particulier de codage a été mis au point. Quant aux langues non alphabétiques (comme le chinois), elles payent un lourd tribut à l’informatique pour n’avoir pas su évoluer vers le système alphabétique…Revenons-en au codage des nombres sur un octet. Nous avons vu qu’un octet pouvait coder 256 nombres différents, par exemple (c’est le choix le plus spontané) la série des entiers de 0 à 255. Comment faire pour, à partir d’un octet, reconstituer le nombre dans la base décimale qui nous est plus familière ? Ce n’est pas sorcier ; il suffit d’appliquer, si on les a bien compris, les principes de la numérotation de position, en gardant à l’esprit que là, la base n’est pas décimale, mais binaire. Prenons un octet au hasard :1 1 0 1 0 0 1 1D'après les principes vus plus haut, ce nombre représente en base dix, en partant de la gauche :1 x 27 + 1 x 26 + 0 x 25 + 1 x 24 + 0 x 23 + 0 x 22 + 1 x 21 + 1 x 20 =1 x 128 + 1 x 64 + 1 x 16 + 1 x 2 + 1 x 1 =128 + 64 + 16 + 2 + 1 =211Et voilà ! Ce n’est pas plus compliqué que cela !Inversement, comment traduire un nombre décimal en codage binaire ? Il suffit de rechercher dans notre nombre les puissances successives de deux. Prenons, par exemple, 186.Dans 186, on trouve 1 x 128, soit 1 x 27. Je retranche 128 de 186 et j’obtiens 58.Dans 58, on trouve 0 x 64, soit 0 x 26. Je ne retranche donc rien.Dans 58, on trouve 1 x 32, soit 1 x 25. Je retranche 32 de 58 et j’obtiens 26.Dans 26, on trouve 1 x 16, soit 1 x 24. Je retranche 16 de 26 et j’obtiens 10.Dans 10, on trouve 1 x 8, soit 1 x 23. Je retranche 8 de 10 et j’obtiens 2.Dans 2, on trouve 0 x 4, soit 0 x 22. Je ne retranche donc rien.Dans 2, on trouve 1 x 2, soit 1 x 21. Je retranche 2 de 2 et j’obtiens 0.Dans 0, on trouve 0 x 1, soit 0 x 20. Je ne retranche donc rien.Il ne me reste plus qu’à reporter ces différents résultats (dans l’ordre !) pour reconstituer l’octet. J’écris alors qu’en binaire, 186 est représenté par :1 0 1 1 1 0 1 0C’est bon ? Alors on passe à la suite.4. Le codage hexadécimalPour en finir avec ce préambule (sinon, cela deviendrait de la gourmandise) , on va évoquer un dernier type de codage, qui constitue une alternative pratique au codage binaire. Il s’agit du codage hexadécimal, autrement dit en base seize.Pourquoi ce choix bizarre ? Tout d’abord, parce que le codage binaire, ce n’est tout de même pas très économique, ni très lisible. Pas très économique : pour représenter un nombre entre 1 et 256, il faut utiliser systématiquement huit chiffres. Pas très lisible : parce que d’interminables suites de 1 et de 0, on a déjà vu plus folichon.Alors, une alternative toute naturelle, c’était de représenter l’octet non comme huit bits (ce que nous avons fait jusque là), mais comme deux paquets de 4 bits (les quatre de gauche, et les quatre de droite). Voyons voir cela de plus près.Avec 4 bits, nous pouvons coder 2 x 2 x 2 x 2 = 16 nombres différents. En base seize, 16 nombres différents se représentent avec un seul chiffre (de même qu’en base 10, dix nombres se représentent avec un seul chiffre).Quels symboles choisir pour les chiffres ? Pour les dix premiers, on n’a pas été chercher bien loin : on a recyclé les dix chiffres de la base décimale. Les dix premiers nombres de la base seize s’écrivent donc tout bêtement 0, 1, 2, 3, 4, 5, 6, 7, 8, et 9. Là, il nous manque encore 6 chiffres, pour représenter les nombres que nous écrivons en décimal 10, 11, 12, 13, 14, 15 et 16. Plutôt qu’inventer de nouveaux symboles (ce qu’on aurait très bien pu faire), on a recyclé les premières lettres de l’alphabet. Ainsi, par convention, A vaut 10, B vaut 11, etc. jusqu’à F qui vaut 15.Or, on s’aperçoit que cette base hexadécimale permet une représentation très simple des octets du binaire. Prenons un octet au hasard :1 0 0 1 1 1 1 0Pour convertir ce nombre en hexadécimal, il y a deux méthodes : l’une consiste à faire un grand détour, en repassant par la base décimale. C’est un peu plus long, mais on y arrive. L’autre méthode consiste à faire le voyage direct du binaire vers l’hexadécimal. Avec l’habitude, c’est nettement plus rapide !Première méthode :On retombe sur un raisonnement déjà abordé. Cet octet représente en base dix :1 x 27 + 0 x 26 + 0 x 25 + 1 x 24 + 1 x 23 + 1 x 22 + 1 x 21 + 0 x 20 =1 x 128 + 1 x 16 + 1 x 8 + 1 x 4 + 1 x 2 + 0 x 1 =128 + 16 + 8 + 4 + 2 =158De là, il faut repartir vers la base hexadécimale.Dans 158, on trouve 9 x 16, c’est-à-dire 9 x 161. Je retranche 144 de 158 et j’obtiens 14.Dans 14, on trouve 14 x 1, c’est-à-dire 14 x 160. On y est.Le nombre s’écrit donc en hexadécimal : 9EDeuxième méthode :Divisons 1 0 0 1 1 1 1 0 en 1 0 0 1 (partie gauche) et 1 1 1 0 (partie droite).1 0 0 1, c’est 8 + 1, donc 91 1 1 0, c’est 8 + 4 + 2 donc 14Le nombre s’écrit donc en hexadécimal : 9E. C’est la même conclusion qu’avec la première méthode. Encore heureux !Le codage hexadécimal est très souvent utilisé quand on a besoin de représenter les octets individuellement, car dans ce codage, tout octet correspond à seulement deux signes.Allez, assez bavardé, on passe aux choses sérieuses : les arcanes de l’algorithmique… votre commentaire
-




|
|
|
|